1. 통계란 무엇인가
우리는 자료의 세계에 살고 있다. TV 등 미디어에서는 매일같이 여론조사 결과, 증권 시장 결과, 그리고 지구 온난화 자료 분석 결과를 발표하고 있으니까. 이러한 조사결과는 자료의 분석에 기반하고 있는데, 자료는 우리에게 어떤 이야기를 말해주고 있다. 그 이야기를 이해하기 위해서는, 통계에 대하여 알아야 할 필요가 있다. 즉 통계는 자료의 수집 및 분석, 그리고 해당 자료로부터 결론을 도출해내는 방법이라고 할 수 있다.
2. Individual과 variable
자료는 크게 individual과 variable로 구성된다.
Individual은 자료에서 설명하고 있는 대상으로, 사람, 동물, 혹은 물건도 될 수 있다.
Variable은 각 individual이 가지고 있는 특성으로, 연령, 성별, 직업 등이 포함된다.
아래의 표는 American Community Survey (ACS)에서 매년 행하는 가구조사 자료의 일부를 가져온 것이다.
| Household (가구) | Region (지역) | Number of people (가구 구성원 수) | Time in dwelling (years) (거주 기간, 년) | Response mode (응답 방법) | Household income (가구 연수입) | Internet access? (인터넷 접속 가능 여부) |
| 425 | Midwest | 5 | 2-4 | Internet | 52,000 | Yes |
| 936459 | West | 4 | 2-4 | 40,500 | Yes | |
| 50055 | Northeast | 2 | 10-19 | Internet | 481,000 | Yes |
| 592934 | West | 4 | 2-4 | Phone | 230,800 | No |
| 545854 | South | 9 | 2-4 | Phone | 33,800 | Yes |
| 809928 | South | 2 | 30+ | Internet | 59,500 | Yes |
| 110157 | Midwest | 1 | 5-9 | Internet | 80,000 | Yes |
위의 표에서 각 행 (row)은 individual로, 각 열 (column)은 variable로 구성되어 있으며, 인터넷에서 찾을 수 있는 대부분의 자료들은 이러한 구성을 따르고 있다.
Variable의 경우, 범주변수 (categorical variable)와 양적변수(quantitative variable)로 구성된다.
Categorical variable은 각 individual에 부여되는 어떤 특성으로, 이 특성에 의해 해당 individual은 특정 카테고리에 속하게 된다. Quantitative variable은 숫자로 나타나는 변수 (예. 갯수 또는 수치)이다.
위의 ACS 표에서 Region, time in dwelling, response mode, internet access status는 categorical variable이고, number of people과 household income은 quantitative variable이다.
주의해야 할 것은 숫자를 가지는 모든 변수가 quantitative variable은 아니라는 것이다. 우편번호(zip code)가 그 예가 될 수 있다. 우편번호는 숫자지만 거주지역의 위치를 표시하는 것이다. 그래서 우편번호는 quantitative variable이 아니라 categorical variable이다. 마찬가지로 ACS표에서 dwelling time은 숫자지만, 거주한 기간을 인터벌 형식(2-4년)으로 표시하고 있기 때문에 categorical variable이다. 만일 이 변수가 인터벌이 아닌 단일 숫자(예. 3)로 표시된다면 해당 변수는 quantitative variable이 될 것이다.
자료분석은 해당 자료의 형태가 categorical인지 quantitative인지에 따라 그래프 등 적합한 방법이 달라진다. 따라서 이 둘을 구별하는 것이 중요하다.
3. 분포(Distribution)
한 변수(variable)은 일반적으로 다양한 값을 가지고 있다. Categorical variable의 경우 각 카테고리별로 동일한 수치를 가지는 경우도 있고 아닌 경우도 있다. 예를 들어, 학생인구 조사에서는 일반적으로 남녀 성비가 동일하지만, 남녀를 포함한 대부분의 학생들은 오른손 잡이인 경우가 있다. Quantitative variable의 경우 각 individual이 동일하거나 유사한 수치를 가질 수도 있고, 다양한 값을 가지는 경우도 있다. 이러한 변수들의 패턴을 통계학에서는 분포(distribution)이라고 부른다. 즉 어느 한 변수의 분포는 해당 변수가 어떤 값들을 어떤 빈도로 가지는지를 보여준다.
아래의 그래프는 10명의 학생들을 대상으로 친구들과 소통할 때 휴대폰(cell phone), Facebook, 직접 만남(in person), 텍스트 메시지(text messaging) 중 어떤 수단을 선호하는지를 조사한 결과이다.
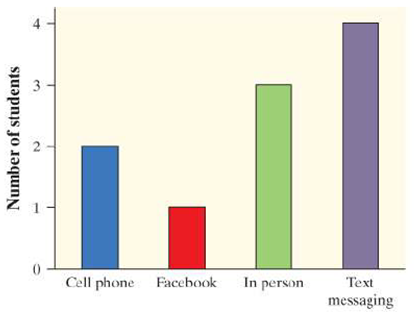
위의 그래프에서 알아야 할 것은 선호수단별 그래프의 길이이다. 텍스트 메시지를 선호하는 학생들의 수가 4명으로 가장 많고, 그래프의 길이도 가장 길다. 반면 Facebook을 선호하는 학생은 2명으로 가장 적으며, 그래프의 길이도 4개 중 가장 짧은 것을 확인할 수 있다.
통계에서 자료 분석은 기본이자 시작이 될 것이다. 기본적인 자료 분석 방법은 다음과 같다.
- 자료에 어떤 변수가 있는지 확인하고 변수들 사이의 관계를 파악할 것
- 그래프를 그리고 수치를 정리할 것
4. 자료 분석에서 추론에 이르기까지
가끔씩 우리는 우리가 가지고 있는 자료로부터 결론을 도출해 내려고 한다. 이것이 추론의 개념이다. 예를 들어서 표본으로 선정된 10명의 학생들 중 9명이 오른손잡이라면 이들의 비율은 표본의 90%이다. 하지만 이 90%의 오른손잡이가 표본을 포함한 전체 학생들을 대표할 수 있을까? 답은 ‘아니오’이다.
표본으로 선정된 또 다른 10명의 경우, 오른손잡이의 비율은 딱 90%가 아닐 수도 있다. 이 경우 우리는 실제 오른손 잡이의 비율이 90%에 가깝다고 말할 수 있을까? 답은 “가깝다”를 어떻게 정의하는가에 따라 달라질 것이다. 결론적으로 우리가 자료로부터 무엇인가를 추론할 수 있는지는 그 자료가 어떻게 생성되었는가에 따라 결정된다.